
item3 - 5 文件上传解析模块1
约 911 字大约 3 分钟
实现大文件的分片上传、断点续传、文件合并以及文档解析功能
目的
- 通过 Redis 和 MinIO 的结合,确保大文件上传的可靠性
- 并通过 Kafka 实现异步处理,进行文件解析等操作
- 模块支持多种文档格式(PDF、Word、Excel)的解析,并提取文本内容用于后续向量化处理
- 文本向量化通过调用阿里向量化 API 实现,生成的向量数据目前存储在
Elasticsearch中,未来将同时支持 FAISS 存储
主要实现功能
文件分片上传与断点续传
技术
前端:
将需要上传的文件进行分片,利用 Fine Uploader 工具将大文件按照 5MB±10% 进行分割传输
后端:
文件状态存储:利用 Redis 的 BitSet 存储各分片的上传状态
对象存储:利用 MinIO 作为分片文件的存储系统
断点续传:Redis 记录分片状态,可以支持客户端中断后继续上传未完成的分片

异步处理 kafka
在成功上传完文件后,就会结束与前端的交互,利用 kafka 来作为消息队列,实现 生产者 - 消费者模型,将 文件合并 和 向量化 任务异步分发
多消费者并行处理,来提升系统吞吐量
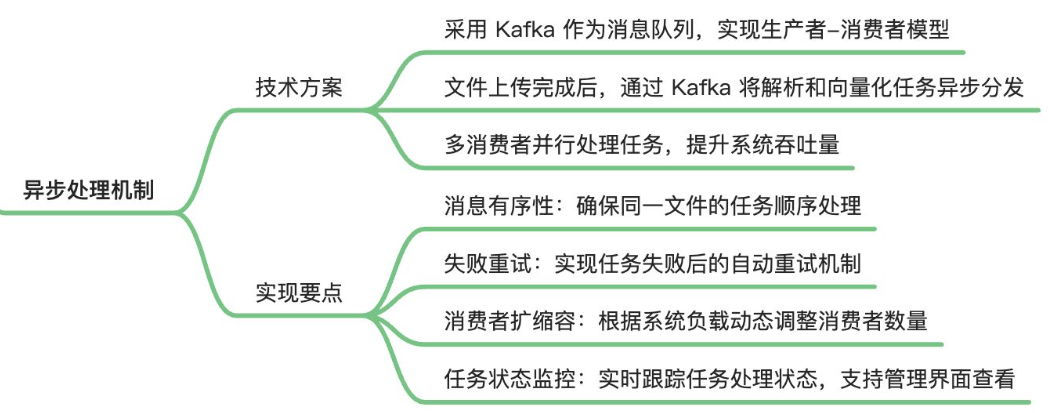
文件合并
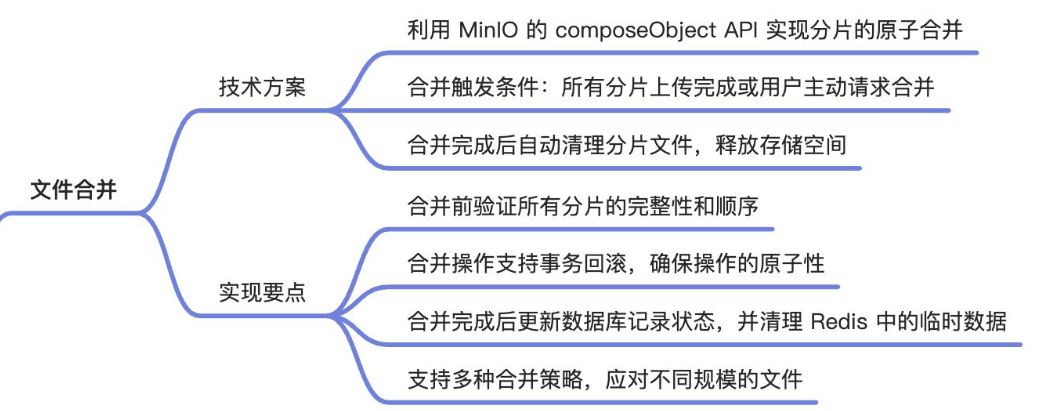
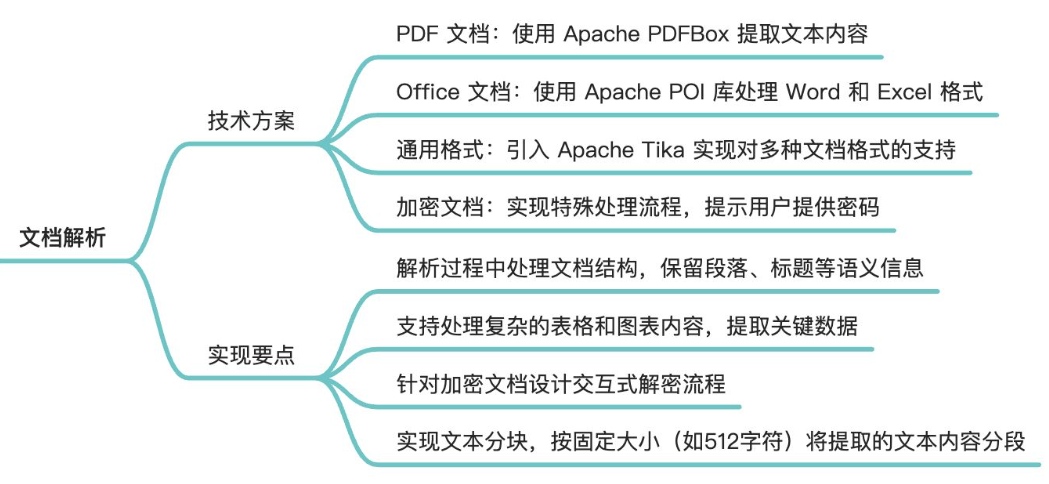
文档解析
利用 Apache PDFBox, Apache POI, Apache Tika 来分别处理解析
按固定大小将提取的文本内容分段
文本向量化
通过调用阿里向量化 API 实现,生成的向量数据目前存储在 Elasticsearch 中
因为需要存的是 2048 维的向量表示,而豆包不支持

文档管理
- 文档删除:支持用户删除已上传的文档以及相关数据
- 权限控制:确保用户只能删除自己的文档,管理员可以删除任何文档
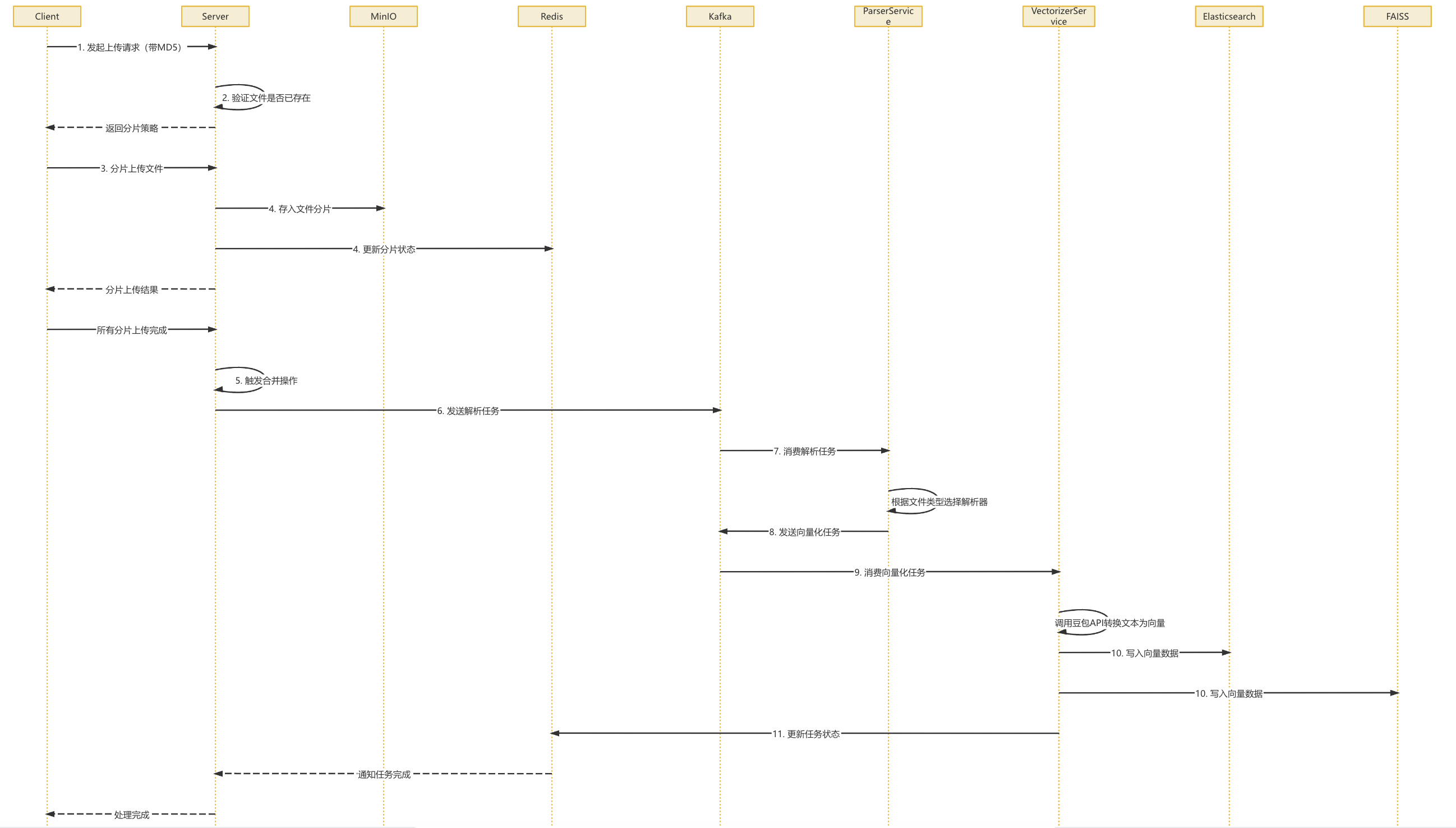
文件上传主要逻辑
- 客户端计算文件 MD5,发起上传请求→服务端验证文件是否已存在,返回分片策略
- 客户端根据策略分片上传文件
- 服务端接收分片,存入 MinIO 并更新 Redis 状态
- 所有分片上传完成后,触发合并操作
- 合并完成后发送解析任务到 Kafka→解析服务消费任务,根据文件类型选择相应解析器提取文本
- 文本分块后发送向量化任务到 Kafka→向量化服务消费任务,调用豆包 API 将文本转换为向量表示
- 向量数据写入 Elasticsearch 和预留 FAISS 接口→更新任务状态,通知用户处理完成
Mysql 数据表
文件主表(file_upload):存储文件元信息,如 MD5、名称、大小、状态
分片表(chunk_info):记录每个分片的信息,包括索引、MD5、存储路径
解析结果表(document_vectors):存储文本分块和向量化结果的元数据
Redis
使用 BitSet 记录已上传分片的位图(SETBIT命令)
存储上传任务的临时状态和进度
缓存热点文件的元数据,减轻数据库压力
MinIO
临时分片:存储上传的文件分片,路径结构为 /temp/{fileMd5}/{chunkIndex}
完整文件:合并后的文件存储在 /documents/{userId}/{fileName}
存储策略:实现热冷数据分离
Elasticsearch
存储文本向量数据和原始文本内容,索引基于文件 MD5 和分块 ID 组织