
item3 - 8 文件解析模块1
实现大文件的分片上传、断点续传、文件合并以及文档解析功能
目的
- 通过 Redis 和 MinIO 的结合,确保大文件上传的可靠性
- 并通过 Kafka 实现异步处理,进行文件解析等操作
- 模块支持多种文档格式(PDF、Word、Excel)的解析,并提取文本内容用于后续向量化处理
- 文本向量化通过调用阿里向量化 API 实现,生成的向量数据目前存储在
Elasticsearch中,未来将同时支持 FAISS 存储
文件处理(解析+向量化)
Producer 消息发送
首先在 Kafka 中会创建两个Topic对应文档解析(file-processing)和向量化(vectorization)
他们的副本和分区都简单设为1
当用户成功把文件chunks均合并好后,会发送信息到 file-processing Topic
合并文件的逻辑在 uploadService.mergeChunks(),MinIO会建立一个临时URL,来允许本地访问该文件,也会返回这个URL
String objectUrl = uploadService.mergeChunks(request.fileMd5(), request.fileName(), userId);
// URL类似
// http://localhost:19000/uploads/merged/original.docx?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=qmY5OyBsIST9I7FLxLug%2F20260122%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20260122T155744Z&X-Amz-Expires=3600&X-Amz-SignedHeaders=host&X-Amz-Signature=e9d553cd260fea9d2449df25ca9fdbb7bef19b53137779de7113b859fc1432b0
之后就把对应信息发送给Kafka Broker
kafkaTemplate.executeInTransaction(kt -> {
kt.send(kafkaConfig.getFileProcessingTopic(), task);
return true;
});
task 是 FileProcessingTask 类,主要包括了文件MD5 | 文件存储路径 | 文件名 | 上传用户ID | 文件所属组织标签 | 文件是否公开 信息
@Data
@AllArgsConstructor
@NoArgsConstructor
public class FileProcessingTask {
private String fileMd5; // 文件的 MD5 校验值
private String filePath; // 文件存储路径
private String fileName; // 文件名
private String userId; // 上传用户ID
private String orgTag; // 文件所属组织标签
private boolean isPublic; // 文件是否公开
/**
* 向后兼容的构造函数
*/
public FileProcessingTask(String fileMd5, String filePath, String fileName) {
this.fileMd5 = fileMd5;
this.filePath = filePath;
this.fileName = fileName;
this.userId = null;
this.orgTag = "DEFAULT";
this.isPublic = false;
}
}
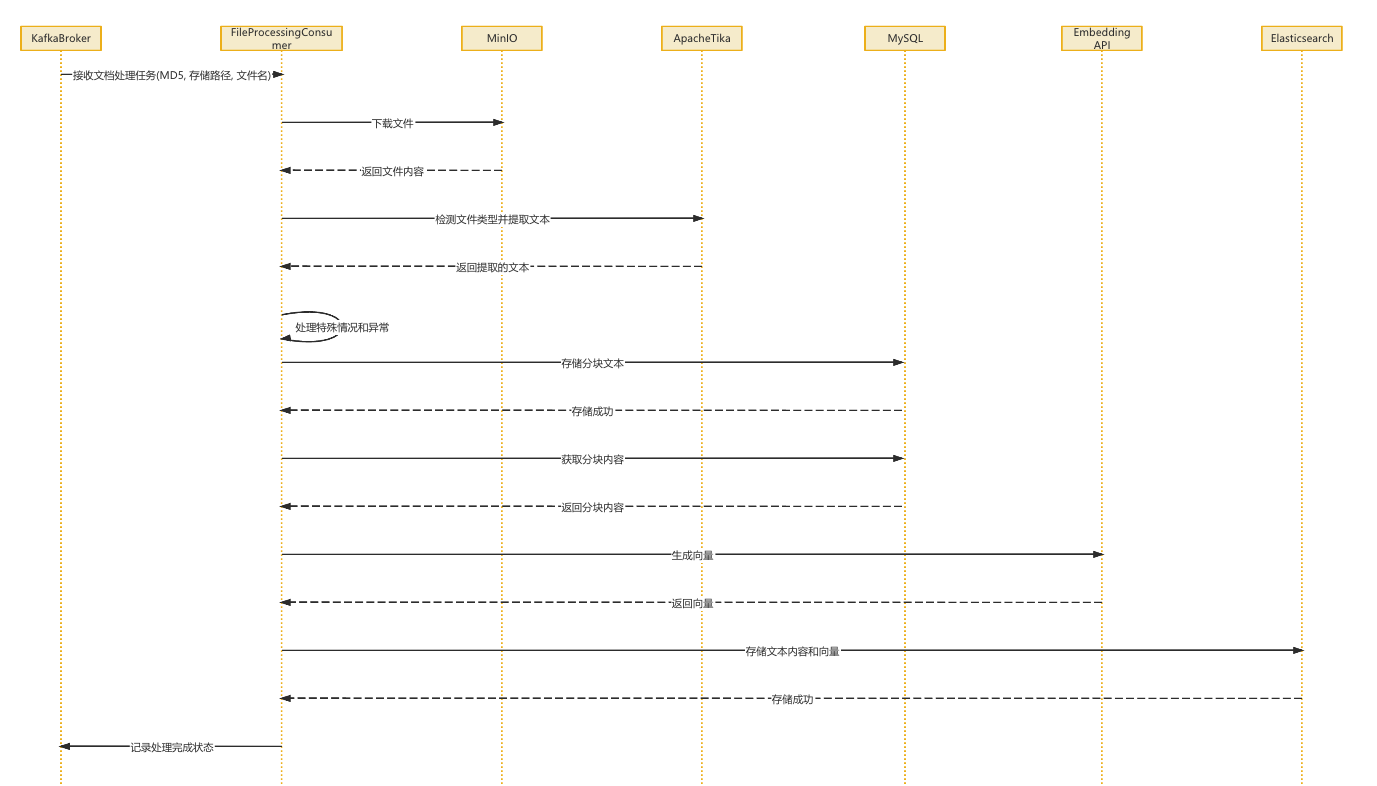
Consumer 消息接收 - FileProcessingConsumer
然后在 FileProcessingConsumer 中由 @Listener 注解来自动监听创建消费者,当对应监听的 Topic 有消息了,就会被消费
@KafkaListener(topics = "#{kafkaConfig.getFileProcessingTopic()}", groupId = "#{kafkaConfig.getFileProcessingGroupId()}")
public void processTask(FileProcessingTask task){...}
根据消息 task 下载文件
task 有对应文件存在MinIO的临时访问链接,基于此去访问获取文件输入流 InputStream
获取后要判断:1. 流是否有内容 2. 转换为可回退流
log.info("Received task: {}", task);
log.info("文件权限信息: userId={}, orgTag={}, isPublic={}",
task.getUserId(), task.getOrgTag(), task.isPublic());
InputStream fileStream = null;
try {
// 下载文件
fileStream = downloadFileFromStorage(task.getFilePath());
// 在 downloadFileFromStorage 返回后立即检查流是否可读
if (fileStream == null) {
throw new IOException("流为空");
}
// 强制转换为可缓存流
// 确保 fileStream 这个输入流拥有“倒带”(回退)的能力
if (!fileStream.markSupported()) {
fileStream = new BufferedInputStream(fileStream);
}
...
}
InputStream 是一个单向的流,默认情况下,读了一个字节,指针就往后移一个,只能往前走,不能回头。
但是,BufferedInputStream 具有 Mark (标记) 和 Reset (重置) 的功能:
- Mark: 在当前位置做一个记号
- Reset: 读取一部分数据后,可以随时调用 reset() 让指针回到刚才做记号的地方,重新读取
目的:
- 文件类型探测
- 性能优化,BufferedInputStream 内部维护了一个内存缓冲区
解析文件 parseService.parseAndSave
因为不可能把整片文章直接保存,这样也不好,不易于后续RAG理解,所以要根据语义或句子进行切割拆分,再放入对应的 document_vectors 数据表中
parseService.parseAndSave(task.getFileMd5(), fileStream,
task.getUserId(), task.getOrgTag(), task.isPublic());
log.info("文件解析完成,fileMd5: {}", task.getFileMd5());
向量化处理 vectorizationService.vectorize
将存入表中分块的数据,依次借用大模型embedding来进行编码,最终存入ElasticSearch
vectorizationService.vectorize(task.getFileMd5(),
task.getUserId(), task.getOrgTag(), task.isPublic());
log.info("向量化完成,fileMd5: {}", task.getFileMd5());
文件拆分存入数据表 parseService.parseAndSave
document_vectors 数据表
每个文档会被切分成多个文本块 (chunk_id),document_vectors 表存储了所有的文本块信息
分两步,首先通过 parseService.parseAndSave 将文本块存入表中,但此时没有编码信息
之后再根据文件MD5作为索引,依次调用 vectorizationService.vectorize 来对文本块进行编码,存入ES中
| 字段名 | 类型 | 描述 |
|---|---|---|
| vector_id | BIGINT AUTO_INCREMENT | 主键,自增ID |
| file_md5 | CHAR(32) | 文件指纹,用于关联file_upload表 |
| chunk_id | INT | 文本分块序号 |
| text_content | LONGTEXT | 原始文本内容 |
| model_version | VARCHAR(32) | 生成向量所使用的模型版本 |
主要流程 (流式文件解析与入库)
通过 Apache Tika 来解析文档
核心目标是:在不占用大量内存的前提下,把一个可能很大的文件(如几百页的 PDF)读出来,拆分成小块,并存入数据库
public void parseAndSave(String fileMd5, InputStream fileStream, String userId, String orgTag, boolean isPublic) throws IOException, TikaException {
logger.info("开始流式解析文件,fileMd5: {}, userId: {}, orgTag: {}, isPublic: {}", fileMd5, userId, orgTag, isPublic);
checkMemoryThreshold();
try (BufferedInputStream bufferedStream = new BufferedInputStream(fileStream, bufferSize)) {
// 创建一个流式处理器,它会在内部处理父块的切分和子块的保存
StreamingContentHandler handler = new StreamingContentHandler(fileMd5, userId, orgTag, isPublic);
Metadata metadata = new Metadata();
ParseContext context = new ParseContext();
AutoDetectParser parser = new AutoDetectParser();
// Tika的parse方法会驱动整个流式处理过程
// 当handler的characters方法接收到足够数据时,会触发分块、切片和保存
parser.parse(bufferedStream, handler, metadata, context);
logger.info("文件流式解析和入库完成,fileMd5: {}", fileMd5);
} catch (SAXException e) {
logger.error("文档解析失败,fileMd5: {}", fileMd5, e);
throw new RuntimeException("文档解析失败", e);
}
}
检查 JVM 堆内存是否充足
Runtime可以获得此时内存情况
如果系统内存快满了,会尝试调用垃圾回收,如果还是不足,直接抛出异常或阻塞,防止因为解析一个大文件导致整个服务 OOM
private void checkMemoryThreshold() {
Runtime runtime = Runtime.getRuntime();
long maxMemory = runtime.maxMemory();
long totalMemory = runtime.totalMemory();
long freeMemory = runtime.freeMemory();
long usedMemory = totalMemory - freeMemory;
double memoryUsage = (double) usedMemory / maxMemory;
if (memoryUsage > maxMemoryThreshold) {
logger.warn("内存使用率过高: {:.2f}%, 触发垃圾回收", memoryUsage * 100);
System.gc();
// 重新检查
usedMemory = runtime.totalMemory() - runtime.freeMemory();
memoryUsage = (double) usedMemory / maxMemory;
if (memoryUsage > maxMemoryThreshold) {
throw new RuntimeException("内存不足,无法处理大文件。当前使用率: " + String.format("%.2f%%", memoryUsage * 100));
}
}
}
BufferedInputStream加快读取
try (BufferedInputStream bufferedStream = new BufferedInputStream(fileStream, bufferSize)) {...}
将传入的原始 fileStream 包装成 BufferedInputStream
目的: 减少 IO 中断
- 原始流读取(如从 S3 或磁盘)可能每次只读几个字节,速度慢且频繁触发 IO 中断。
- BufferedInputStream 相当于一个“蓄水池”,一次性取一大勺水 (大小为预定的
bufferSize) 放在内存里,解析器从内存取水,速度极快
使用 try-with-resources 语法,确保无论解析成功还是失败,流都会被自动关闭
组装解析流水线 (Apache Tika)
// 创建一个流式处理器,它会在内部处理父块的切分和子块的保存
StreamingContentHandler handler = new StreamingContentHandler(fileMd5, userId, orgTag, isPublic);
Metadata metadata = new Metadata();
ParseContext context = new ParseContext();
AutoDetectParser parser = new AutoDetectParser();
这里组装了 Tika 的四个配置:
parser (AutoDetectParser): “总指挥”。它负责识别文件类型(是 PDF 还是 Word),并调用对应的底层解析逻辑。
handler (StreamingContentHandler): “搬运工 + 加工厂”(自己自定义的核心类)
- 它不产生数据,它只接收数据。
- 它的内部逻辑是:接收字符 -> 攒够一定数量 -> 切分 -> 存数据库 -> 清空缓冲区。
metadata: 用于接收文件的属性(如作者、标题、修改时间)。虽然代码里没怎么用,但 Tika 必须要求传这个参数。
context: 解析器的配置上下文
开始解析文档
parser.parse(bufferedStream, handler, metadata, context);
运行到这里,控制权移交给 Tika 的 parser
- parser 读取 bufferedStream 中的一段二进制数据
- parser 将其转换为文本
- parser 主动调用 handler 的方法(如 handler.characters(...)),把文本“喂”给 handler
- handler 在接收到文本的同时,实时进行切分和入库操作
自定义 handler
只有自定义 handler 来实现对文档的流式解析,从而逐步将其分片,然后将内容存入数据表中
/**
* 内部流式内容处理器,实现了父子文档切分策略的核心逻辑。
* Tika解析器会调用characters方法,当累积的文本达到"父块"大小时,
* 就触发processParentChunk方法,进行"子切片"的生成和入库。
*/
private class StreamingContentHandler extends BodyContentHandler {
private final StringBuilder buffer = new StringBuilder();
private final String fileMd5;
private final String userId;
private final String orgTag;
private final boolean isPublic;
private int savedChunkCount = 0;
public StreamingContentHandler(String fileMd5, String userId, String orgTag, boolean isPublic) {
super(-1); // 禁用Tika的内部写入限制,我们自己管理缓冲区
this.fileMd5 = fileMd5;
this.userId = userId;
this.orgTag = orgTag;
this.isPublic = isPublic;
}
@Override
public void characters(char[] ch, int start, int length) {
buffer.append(ch, start, length);
if (buffer.length() >= parentChunkSize) {
processParentChunk();
}
}
@Override
public void endDocument() {
// 处理文档末尾剩余的最后一部分内容
if (buffer.length() > 0) {
processParentChunk();
}
}
private void processParentChunk() {
String parentChunkText = buffer.toString();
logger.debug("处理父文本块,大小: {} bytes", parentChunkText.length());
// 1. 将父块分割成更小的、有语义的子切片
List<String> childChunks = ParseService.this.splitTextIntoChunksWithSemantics(parentChunkText, chunkSize);
// 2. 将子切片批量保存到数据库
this.savedChunkCount = ParseService.this.saveChildChunks(fileMd5, childChunks, userId, orgTag, isPublic, this.savedChunkCount);
// 3. 清空缓冲区,为下一个父块做准备
buffer.setLength(0);
}
}
当调用了 parser.parse 就开始不断解析文档
parser 负责将文档转为字符流,然后调用 handler.characters() 存入 buffer 中,直到最后一部分结束
而 handler 就是不断接受,但是会由逻辑进行判断, 字符存了一定量了,就会触发解析逻辑 processParentChunk()
@Override
public void characters(char[] ch, int start, int length) {
buffer.append(ch, start, length);
if (buffer.length() >= parentChunkSize) {
processParentChunk();
}
}
一次性存入 buffer 的就相当于父文本块,比较大,然后就需要调用解析逻辑来拆分成更小的、有语义的子切片,然后将子切片批量保存到数据库
最后把这个 buffer 清空,然后继续
private void processParentChunk() {
String parentChunkText = buffer.toString();
logger.debug("处理父文本块,大小: {} bytes", parentChunkText.length());
// 1. 将父块分割成更小的、有语义的子切片
List<String> childChunks = ParseService.this.splitTextIntoChunksWithSemantics(parentChunkText, chunkSize);
// 2. 将子切片批量保存到数据库
this.savedChunkCount = ParseService.this.saveChildChunks(fileMd5, childChunks, userId, orgTag, isPublic, this.savedChunkCount);
// 3. 清空缓冲区,为下一个父块做准备
buffer.setLength(0);
}
endDocument 是为了避免有省的,即Tika读完了最后一部分,但并没有触发解析逻辑,那么就会调用这个
内部父文本切割逻辑 ParseService.this.splitTextIntoChunksWithSemantics(...)
当在 StreamingContentHandler 的代码块里写代码时:
- 单独写 this: 指的是 StreamingContentHandler 这个对象自己
- 写 ParseService.this: 指的是 创建了这个 Handler 的那个 ParseService 对象
切割逻辑如下:
它的核心思想是:尽量不打断段落,实在不行才打断句子,再不行才强制切断
(预先设定了好了一个小文本块的大小 chunkSize)先按照段落进行分割,然后依次遍历每个段落
若整个段落很大,大于了
chunkSize,那么需要再进行更细致地切割先将当前的chunk保存,然后对当前的段落进一步切割 (根据符号分,如句号、感叹号等,如句子也长,再按词分割 HanLP StandardTokenizer进行分词),切出来的句子块直接加入结果集
如果当前 chunk 还行,但是塞不下整个段落了,那么把当前chunk先存入,然后放入新的chunk
还能塞得下当前chunk,那直接放进去
/**
* 智能文本分割,保持语义完整性
*/
private List<String> splitTextIntoChunksWithSemantics(String text, int chunkSize) {
List<String> chunks = new ArrayList<>();
// 按段落分割
String[] paragraphs = text.split("\n\n+");
StringBuilder currentChunk = new StringBuilder();
for (String paragraph : paragraphs) {
// 如果单个段落超过chunk大小,需要进一步分割
if (paragraph.length() > chunkSize) {
// 先保存当前chunk
if (currentChunk.length() > 0) {
chunks.add(currentChunk.toString().trim());
currentChunk = new StringBuilder();
}
// 按句子分割长段落
List<String> sentenceChunks = splitLongParagraph(paragraph, chunkSize);
chunks.addAll(sentenceChunks);
}
// 如果添加这个段落会超过chunk大小
else if (currentChunk.length() + paragraph.length() > chunkSize) {
// 保存当前chunk
if (currentChunk.length() > 0) {
chunks.add(currentChunk.toString().trim());
}
// 开始新chunk
currentChunk = new StringBuilder(paragraph);
}
// 可以添加到当前chunk
else {
if (currentChunk.length() > 0) {
currentChunk.append("\n\n");
}
currentChunk.append(paragraph);
}
}
// 添加最后一个chunk
if (currentChunk.length() > 0) {
chunks.add(currentChunk.toString().trim());
}
return chunks;
}
将所有子块存入数据表 document_vectors
在 handler buffer 满了时,触发解析逻辑后,会先分割成子切片,然后将其批量保存到数据表 document_vectors 中
this.savedChunkCount 在默认是0开始,然后不断累积,记录总保存 chunk 数量
this.savedChunkCount = ParseService.this.saveChildChunks(fileMd5, childChunks, userId, orgTag, isPublic, this.savedChunkCount);
对应的保存逻辑,就遍历然后依次保存
/**
* 将子切片列表保存到数据库。
*
* @param fileMd5 文件的 MD5 哈希值
* @param chunks 子切片文本列表
* @param userId 上传用户ID
* @param orgTag 组织标签
* @param isPublic 是否公开
* @param startingChunkId 当前批次的起始分片ID
* @return 保存后总的分片数量
*/
private int saveChildChunks(String fileMd5, List<String> chunks, String userId, String orgTag, boolean isPublic, int startingChunkId) {
int currentChunkId = startingChunkId;
for (String chunk : chunks) {
currentChunkId++;
var vector = new DocumentVector();
vector.setFileMd5(fileMd5);
vector.setChunkId(currentChunkId);
vector.setTextContent(chunk);
vector.setUserId(userId);
vector.setOrgTag(orgTag);
vector.setPublic(isPublic);
documentVectorRepository.save(vector);
}
logger.info("成功保存 {} 个子切片到数据库", chunks.size());
return currentChunkId;
}
(好像有点问题 N+1 插入问题)
- 使用 JPA 的 saveAll
- 使用 JdbcTemplate