
item3 - 7 文件上传解析模块3
实现大文件的分片上传、断点续传、文件合并以及文档解析功能
目的
- 通过 Redis 和 MinIO 的结合,确保大文件上传的可靠性
- 并通过 Kafka 实现异步处理,进行文件解析等操作
- 模块支持多种文档格式(PDF、Word、Excel)的解析,并提取文本内容用于后续向量化处理
- 文本向量化通过调用阿里向量化 API 实现,生成的向量数据目前存储在
Elasticsearch中,未来将同时支持 FAISS 存储
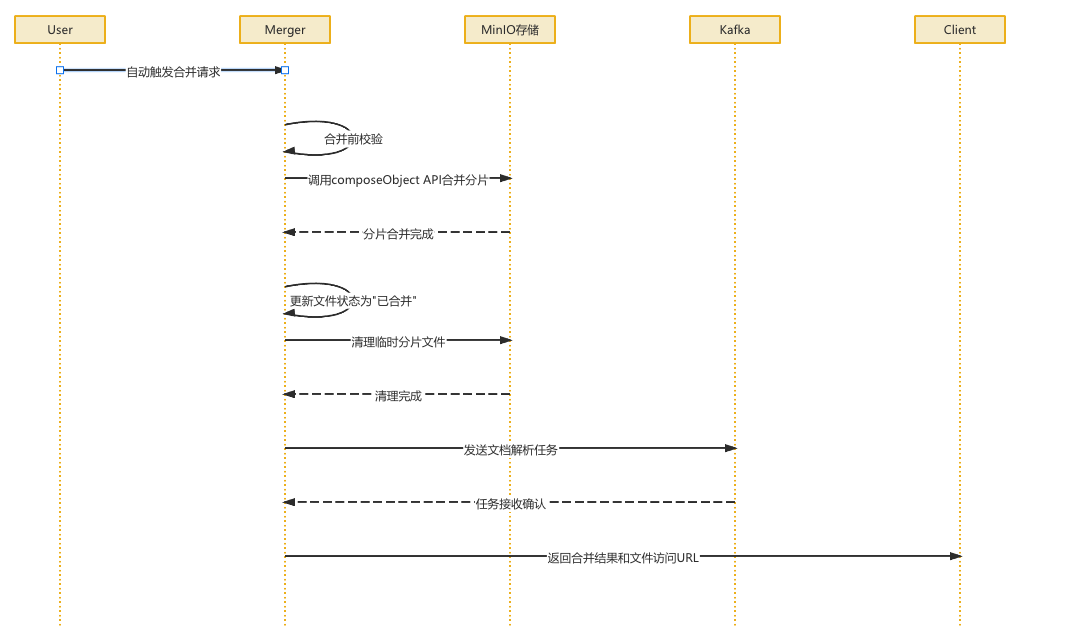
文件合并
会自动触发,应该是每次成功上传完分片会检查是否全部完成了 (检查逻辑在前端)
当收到用户的 merge 请求后,会先进行校验,然后调用 MinIO 的 composeObject API 来进行合并
合并成功后,去 file_upload表 更新文件的状态,同时去 MinIO 中清理临时分片文件
最后通过 Kafka 发送文档解析任务进行异步处理
然后返回请求,合并结果和文件访问URL
前端分析
前端在完成文件上传后,会检查是否所有分片均成功, 然后尝试发起文件合并请求
if (data.uploaded.length === totalChunks) {
const success = await mergeFile(task);
if (!success) return false;
}
async function mergeFile(task: Api.KnowledgeBase.UploadTask) {
try {
const { error } = await request({
url: '/upload/merge',
method: 'POST',
data: { fileMd5: task.fileMd5, fileName: task.fileName }
});
if (error) return false;
// 更新任务状态为已完成
const index = tasks.value.findIndex(t => t.fileMd5 === task.fileMd5);
tasks.value[index].status = UploadStatus.Completed;
return true;
} catch {
return false;
}
}
MinIO
在使用时,用的是 MinioClient 对象
MinIO 是一个高性能的对象存储系统,设计初衷是作为云原生存储系统的替代方案
对象存储的概念与标准 Unix 文件系统类似,但 它使用的是"桶(bucket)"和"对象(object)"的概念,而不是目录和文件
桶可以像目录一样嵌套形成层级结构,而对象则是一组任意的字节数据,可以是图片、PDF 或其他任何文件类型
与文件系统类似,桶和对象也可以设置权限,实现细粒度的访问控制
在安装好 MinIO 后,可以去基于 Web 的管理控制台访问管理
MinIO JAVA SDK
不过在 JAVA 中更多的是通过 Java SDK 使用 MinIO
首先在项目中添加依赖:
<dependency>
<groupId>io.minio</groupId>
<artifactId>minio</artifactId>
<version>8.5.2</version>
</dependency>
之后,通过 Spring 的 @Value 以及 @Bean等注释,来自动注册一个 MinIOClient 的实例,用于之后的操作
主要配置文件在 MinioConfig
@Configuration
public class MinioConfig {
@Value("${minio.endpoint}")
private String endpoint;
@Value("${minio.accessKey}")
private String accessKey;
@Value("${minio.secretKey}")
private String secretKey;
@Value("${minio.publicUrl}")
private String publicUrl;
@Bean
public MinioClient minioClient() {
return MinioClient.builder()
// 端口,存储地址
.endpoint(endpoint)
// 公钥和秘钥
.credentials(accessKey, secretKey)
.build();
}
@Bean
public String minioPublicUrl() {
return publicUrl;
}
}
主要API
桶操作
bucketExists(BucketExistsArgs): 检查某个桶是否存在。makeBucket(MakeBucketArgs): 创建新桶。listBuckets(): 列出当前账号下所有的桶。removeBucket(RemoveBucketArgs): 删除空桶。
注意:在上传文件前,通常会先调用 bucketExists 检查,不存在则调用 makeBucket 创建
对象操作
这是最频繁使用的部分,用于处理实际的文件
- 上传
putObject(PutObjectArgs): 最通用的上传接口,支持从 InputStream 上传uploadObject(UploadObjectArgs): 直接从本地磁盘文件路径上传,效率更高
- 下载与查看
getObject(GetObjectArgs): 获取文件的输入流(InputStream),用于后端处理文件内容。statObject(StatObjectArgs): 获取元数据(文件大小、最后修改时间、Content-Type 等),但不下载文件本身。
- 列表与删除
listObjects(ListObjectsArgs): 遍历桶内的文件removeObject(RemoveObjectArgs): 删除单个对象removeObjects(RemoveObjectsArgs): 批量删除
预签名操作
是 MinIO 非常强大的一类 API,主要解决 “权限安全” 问题。
getPresignedObjectUrl(GetPresignedObjectUrlArgs): 生成一个带有时效性的 HTTP GET 链接场景: 你的文件是私有的,但你想让用户在接下来的 10 分钟内可以点击查看一张图片
简单示例
// 构建上传参数
minioClient.putObject(
PutObjectArgs.builder()
.bucket("my-bucket")
.object("test.jpg")
.stream(inputStream, size, -1) // -1 表示不限制分片大小
.contentType("image/jpeg") // 设置文件类型,方便浏览器直接预览
.build()
);
后端分析
当前端把所有文件chunk均上传后,会自动发送文件合并请求,POST /api/v1/upload/merge 来触发后端文件合并逻辑
临时的chunk存放在 MinIO 中,需要将他们合并
临时分片:存储上传的文件分片,路径结构为
/temp/{fileMd5}/{chunkIndex}完整文件:合并后的文件存储在
/documents/{userId}/{fileName}
当合并结束了,会向 Kafka 发送一个任务来异步解析该文档向量化
文件合并接口:
URL:
/api/v1/upload/mergeMethod: POST
Headers: Bearer
Request Body:
{ "file_md5": "d41d8cd98f00b204e9800998ecf8427e", "file_name": "年度报告.pdf" }Response
<!-- 成功 --> { "code": 200, "message": "File merged successfully", "data": { "object_url": "https://minio.example.com/reports/年度报告.pdf", "file_size": 15728640 } } <!-- 失败 --> { "code": 400, "message": "Not all chunks have been uploaded" }
Contorller层 UploadController
UploadController/uploadChunk - /merge接口
当所有chunk上传完毕,会收到前端的 merge 请求
相关参数
主要两个,分别是 文件的 MD5 以及 文件的名字
userId 则是组织过滤器塞到请求里的
/**
* 合并请求的辅助类,包含文件的MD5值和文件名
* 作为 DTO (Data Transfer Object,数据传输对象),用来接收前端发来的 JSON 数据
*/
public record MergeRequest(String fileMd5, String fileName) {}
/**
* 合并文件分片接口
*
* @param request 包含文件MD5和文件名的请求体
* @param userId 当前用户ID
* @return 返回包含合并后文件访问URL的响应
*/
@Transactional
@PostMapping("/merge")
public ResponseEntity<Map<String, Object>> mergeFile(
@RequestBody MergeRequest request,
@RequestAttribute("userId") String userId) {...}
检查文件完整性与权限校验
根据请求传来文件名和对应的用户id去 file_upload表进行检查
直接通过 FileUploadRepository 的 findByFileMd5AndUserId(request.fileMd5(), userId) 方法来获取对应的 fileUpload 对象(文件上传实体类)
若 fileUpload 不存在,那么必然是失败的
当得到了 fileUpload 对象,那么进一步需要判断用户是否有权限,只有 文件对应用户才可以合并该文件
LogUtils.PerformanceMonitor monitor = LogUtils.startPerformanceMonitor("MERGE_FILE");
try {
String fileType = getFileType(request.fileName());
LogUtils.logBusiness("MERGE_FILE", userId, "接收到合并文件请求: fileMd5=%s, fileName=%s, fileType=%s", request.fileMd5(), request.fileName(), fileType);
// 检查文件完整性和权限
LogUtils.logBusiness("MERGE_FILE", userId, "检查文件记录和权限: fileMd5=%s, fileName=%s", request.fileMd5(), request.fileName());
FileUpload fileUpload = fileUploadRepository.findByFileMd5AndUserId(request.fileMd5(), userId).orElseThrow(() -> {
LogUtils.logUserOperation(userId, "MERGE_FILE", request.fileMd5(), "FAILED_FILE_NOT_FOUND");
return new RuntimeException("文件记录不存在");
});
// 确保用户有权限操作该文件
if (!fileUpload.getUserId().equals(userId)) {
LogUtils.logUserOperation(userId, "MERGE_FILE", request.fileMd5(), "FAILED_PERMISSION_DENIED");
LogUtils.logBusiness("MERGE_FILE", userId, "权限验证失败: 尝试合并不属于自己的文件, fileMd5=%s, fileName=%s, 实际所有者=%s",
request.fileMd5(), request.fileName(), fileUpload.getUserId());
monitor.end("合并失败:权限不足");
Map<String, Object> errorResponse = new HashMap<>();
errorResponse.put("code", HttpStatus.FORBIDDEN.value());
errorResponse.put("message", "没有权限操作此文件");
return ResponseEntity.status(HttpStatus.FORBIDDEN).body(errorResponse);
}
LogUtils.logBusiness("MERGE_FILE", userId, "权限验证通过,开始合并文件: fileMd5=%s, fileName=%s, fileType=%s", request.fileMd5(), request.fileName(), fileType);
...
}
检查分片是否全部上传完成
通过 UploadService 的 getUploadedChunks 方法获取成功上传的chunks索引 (从Redis获取) 以及 getTotalChunks 方法获取该文件的总chunk数量
两者对比来判断分片是否全部上传完成
// 检查分片是否全部上传完成
List<Integer> uploadedChunks = uploadService.getUploadedChunks(request.fileMd5(), userId);
int totalChunks = uploadService.getTotalChunks(request.fileMd5(), userId);
LogUtils.logBusiness("MERGE_FILE", userId, "分片上传状态: fileMd5=%s, fileName=%s, 已上传=%d/%d", request.fileMd5(), request.fileName(), uploadedChunks.size(), totalChunks);
if (uploadedChunks.size() < totalChunks) {
LogUtils.logUserOperation(userId, "MERGE_FILE", request.fileMd5(), "FAILED_INCOMPLETE_CHUNKS");
monitor.end("合并失败:分片未全部上传");
Map<String, Object> errorResponse = new HashMap<>();
errorResponse.put("code", HttpStatus.BAD_REQUEST.value());
errorResponse.put("message", "文件分片未全部上传,无法合并");
return ResponseEntity.status(HttpStatus.BAD_REQUEST).body(errorResponse);
}
合并文件
通过 uploadService.mergeChunks 方法来实现文件的合并,所需参数为该文件的Md5和文件名以及用户id
实现在MinIO的合并,以及删除临时chunk,最终返回该总文件存储的位置URL
// 合并文件
LogUtils.logBusiness("MERGE_FILE", userId, "开始合并文件分片: fileMd5=%s, fileName=%s, fileType=%s, 分片数量=%d", request.fileMd5(), request.fileName(), fileType, totalChunks);
String objectUrl = uploadService.mergeChunks(request.fileMd5(), request.fileName(), userId);
LogUtils.logFileOperation(userId, "MERGE", request.fileName(), request.fileMd5(), "SUCCESS");
将解析任务发送至 Kafka
先构建了一个 FileProcessingTask 对象,包含了当前文件的Md5、MinIO的存储位置、文件名称、用户Id、用户组织标签、文件是否公开的信息
然后直接调用Kafka对应API将该任务发送到 kafkaConfig.getFileProcessingTopic() Topic中
kafkaTemplate.executeInTransaction(kt -> {
kt.send(kafkaConfig.getFileProcessingTopic(), task);
return true;
});
相关代码:
// 发送任务到 Kafka,包含完整的权限信息
LogUtils.logBusiness("MERGE_FILE", userId, "创建文件处理任务: fileMd5=%s, fileName=%s, fileType=%s, orgTag=%s, isPublic=%s", request.fileMd5(), request.fileName(), fileType, fileUpload.getOrgTag(), fileUpload.isPublic());
FileProcessingTask task = new FileProcessingTask(
request.fileMd5(),
objectUrl,
request.fileName(),
fileUpload.getUserId(),
fileUpload.getOrgTag(),
fileUpload.isPublic()
);
LogUtils.logBusiness("MERGE_FILE", userId, "发送文件处理任务到Kafka(事务): topic=%s, fileMd5=%s, fileName=%s", kafkaConfig.getFileProcessingTopic(), request.fileMd5(), request.fileName());
kafkaTemplate.executeInTransaction(kt -> {
kt.send(kafkaConfig.getFileProcessingTopic(), task);
return true;
});
LogUtils.logBusiness("MERGE_FILE", userId, "文件处理任务已发送: fileMd5=%s, fileName=%s, fileType=%s", request.fileMd5(), request.fileName(), fileType);
对应设计了一个文件处理的任务类 (FileProcessingTask), 用于Kafka消息传递
/**
* 文件处理任务类,用于Kafka消息传递
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class FileProcessingTask {
private String fileMd5; // 文件的 MD5 校验值
private String filePath; // 文件存储路径
private String fileName; // 文件名
private String userId; // 上传用户ID
private String orgTag; // 文件所属组织标签
private boolean isPublic; // 文件是否公开
/**
* 向后兼容的构造函数
*/
public FileProcessingTask(String fileMd5, String filePath, String fileName) {
this.fileMd5 = fileMd5;
this.filePath = filePath;
this.fileName = fileName;
this.userId = null;
this.orgTag = "DEFAULT";
this.isPublic = false;
}
}
返回成功响应
如果没有异常,所有操作成功,那么会构建成功响应,返回文件的对应URL路径
// 构建数据对象
Map<String, Object> data = new HashMap<>();
data.put("object_url", objectUrl);
// 构建统一响应格式
Map<String, Object> response = new HashMap<>();
response.put("code", 200);
response.put("message", "文件合并成功,任务已发送到 Kafka");
response.put("data", data);
LogUtils.logUserOperation(userId, "MERGE_FILE", request.fileMd5(), "SUCCESS");
monitor.end("文件合并成功");
return ResponseEntity.ok(response);
异常处理
对于上面操作可能存在的异常,会统一进行捕获
返回 500 响应和对应原因
catch (Exception e) {
String fileType = getFileType(request.fileName());
LogUtils.logBusinessError("MERGE_FILE", userId, "文件合并失败: fileMd5=%s, fileName=%s, fileType=%s", e,
request.fileMd5(), request.fileName(), fileType);
monitor.end("文件合并失败: " + e.getMessage());
Map<String, Object> errorResponse = new HashMap<>();
errorResponse.put("code", HttpStatus.INTERNAL_SERVER_ERROR.value());
errorResponse.put("message", "文件合并失败: " + e.getMessage());
return ResponseEntity.status(HttpStatus.INTERNAL_SERVER_ERROR).body(errorResponse);
}
Service层 UploadService
主要在 Controller 层用到了三个方法
getUploadedChunks(request.fileMd5(), userId)来获取成功上传的chunks索引getTotalChunks(request.fileMd5(), userId)获取该MD5对应文件的总chunk数量mergeChunks(request.fileMd5(), request.fileName(), userId)实现文件合并逻辑
getUploadedChunks 在文件上传时分析过,主要就是从Redis缓存中获取对应的BitMap值然后转换
getTotalChunks 获取文件的总 chunk 数量 也分析过
所以重点分析 mergeChunks 方法
主要参数
主要就是文件的 MD5 和文件名以及用户的ID信息
最终返回的是存在 MinIO 的文件路径
/**
* 合并所有分片
*
* @param fileMd5 文件的 MD5 值
* @param fileName 文件名
* @param userId 用户ID
* @return 合成文件的访问 URL
*/
public String mergeChunks(String fileMd5, String fileName, String userId) { ... }
主要步骤
调用 MinIO 合并 -> 清理 MinIO 中的分片 -> 删除 Redis 缓存 -> 更新数据库状态为“已完成”
- 根据文件的MD5,去
chunk_info表中获取所有被记录在表里的 chunk 的信息List<ChunkInfo> - 然后调用
getTotalChunks来获取总切片数,进一步与前面得到的列表比较,检查数量是否一致 (Controller层只是检查了 小于) - 检验完毕后,根据所有chunk的路径列表,去 MinIO 检查是否成功存储了
- 随后,设置 合并路径 (
mergedPath = "merged/" + fileName) - 开始合并文件,利用 MinIO 的
ComposeSource来合并所有chunk - 检查合并后的文件
minioClient.statObject - 清理分片文件
- 删除 Redis 中的分片状态的缓存记录
- 更新文件状态为 1 表示已完成
- 生成预签名 URL(有效期为 1 小时)
- 最终返回这个 URL
检查所有chunk是否均已保存
从 chunk_info表根据所给文件的Md5升序排序获得所有存在数据表中的对应文件的chunk的信息,为一个 List 集合 List<ChunkInfo>
再利用 getTotalChunks 根据文件Md5和用户id去对应的 file_upload 表得到文件的大小信息,再以 int chunkSize = 5 * 1024 * 1024; 默认计算对应的预期chunk数量
与前面从 chunk_info 中获取的size进行对比
String fileType = getFileType(fileName);
logger.info("开始合并文件分片 => fileMd5: {}, fileName: {}, fileType: {}, userId: {}", fileMd5, fileName, fileType, userId);
try {
// 查询所有分片信息
logger.debug("查询分片信息 => fileMd5: {}, fileName: {}", fileMd5, fileName);
List<ChunkInfo> chunks = chunkInfoRepository.findByFileMd5OrderByChunkIndexAsc(fileMd5);
logger.info("查询到分片信息 => fileMd5: {}, fileName: {}, fileType: {}, 分片数量: {}", fileMd5, fileName, fileType, chunks.size());
// 检查分片数量是否与预期一致
int expectedChunks = getTotalChunks(fileMd5, userId);
if (chunks.size() != expectedChunks) {
logger.error("分片数量不匹配 => fileMd5: {}, fileName: {}, fileType: {}, 期望: {}, 实际: {}",
fileMd5, fileName, fileType, expectedChunks, chunks.size());
throw new RuntimeException(String.format("分片数量不匹配,期望: %d, 实际: %d", expectedChunks, chunks.size()));
}
...
}
获取所有chunk临时路径
利用 stream 机制从 chunks 列表获取所有chunk的存储路径
List<String> partPaths = chunks.stream()
.map(ChunkInfo::getStoragePath)
.collect(Collectors.toList());
logger.debug("分片路径列表 => fileMd5: {}, fileName: {}, 路径数量: {}", fileMd5, fileName, partPaths.size());
检查MinIO中是否存储了所有chunk
利用的是 minioClient.statObject() 方法来得到 StatObjectResponse 对象
如果查找的chunk不存在,会抛出异常,进而被捕获
// 检查每个分片是否存在
logger.info("开始检查每个分片是否存在 => fileMd5: {}, fileName: {}, fileType: {}", fileMd5, fileName, fileType);
for (int i = 0; i < partPaths.size(); i++) {
String path = partPaths.get(i);
try {
StatObjectResponse stat = minioClient.statObject(
StatObjectArgs.builder()
.bucket("uploads")
.object(path)
.build()
);
logger.debug("分片存在 => fileName: {}, index: {}, path: {}, size: {}", fileName, i, path, stat.size());
} catch (Exception e) {
logger.error("分片不存在或无法访问 => fileName: {}, index: {}, path: {}, 错误: {}", fileName, i, path, e.getMessage(), e);
throw new RuntimeException("分片 " + i + " 不存在或无法访问: " + e.getMessage(), e);
}
}
logger.info("分片检查完成,所有分片都存在 => fileMd5: {}, fileName: {}, fileType: {}", fileMd5, fileName, fileType);
根据mergedPath开始合并chunks
会在原先的 try 语句块再包一层 try
先基于所有chunks的存储路径,构建一个 ComposeSource 列表 (需要合并的文件) List<ComposeSource>
然后调用 minioClient.composeObject() 方法, 传入 ComposeObjectArgs 对象来设置合并文件即可
sources 列表中的顺序决定了最终合并文件的内容顺序
try {
// 合并分片
List<ComposeSource> sources = partPaths.stream()
.map(path -> ComposeSource.builder().bucket("uploads").object(path).build())
.collect(Collectors.toList());
logger.debug("构建合并请求 => fileMd5: {}, fileName: {}, targetPath: {}, sourcePaths: {}", fileMd5, fileName, mergedPath, partPaths);
minioClient.composeObject(
ComposeObjectArgs.builder()
.bucket("uploads")
.object(mergedPath)
.sources(sources)
.build()
);
logger.info("分片合并成功 => fileMd5: {}, fileName: {}, fileType: {}, mergedPath: {}", fileMd5, fileName, fileType, mergedPath);
...
}
检查合并文件是否成功然后清理chunks
还是用 minioClient.statObject 来尝试获取合并后的文件,如果获取不到就会报错被捕获,说明合并失败了,那么就不会清理chunks
合并成功并合并的文件存在,那么就可以把存在临时目录里的文件清理了,依次循环遍历路径,调用 minioClient.removeObject 来清理
// 检查合并后的文件
StatObjectResponse stat = minioClient.statObject(
StatObjectArgs.builder()
.bucket("uploads")
.object(mergedPath)
.build()
);
logger.info("合并文件信息 => fileMd5: {}, fileName: {}, fileType: {}, path: {}, size: {}", fileMd5, fileName, fileType, mergedPath, stat.size());
// 清理分片文件
logger.info("开始清理分片文件 => fileMd5: {}, fileName: {}, 分片数量: {}", fileMd5, fileName, partPaths.size());
for (String path : partPaths) {
try {
minioClient.removeObject(
RemoveObjectArgs.builder()
.bucket("uploads")
.object(path)
.build()
);
logger.debug("分片文件已删除 => fileName: {}, path: {}", fileName, path);
} catch (Exception e) {
// 记录错误但不中断流程
logger.warn("删除分片文件失败,将继续处理 => fileName: {}, path: {}, 错误: {}", fileName, path, e.getMessage());
}
}
logger.info("分片文件清理完成 => fileMd5: {}, fileName: {}, fileType: {}", fileMd5, fileName, fileType);
合并成功,先删除Redis分片记录
// 删除 Redis 中的分片状态记录
logger.info("删除Redis中的分片状态记录 => fileMd5: {}, fileName: {}, userId: {}", fileMd5, fileName, userId);
deleteFileMark(fileMd5, userId);
logger.info("分片状态记录已删除 => fileMd5: {}, fileName: {}, userId: {}", fileMd5, fileName, userId);
...
/**
* 删除文件所有分片上传标记
*
* @param fileMd5 文件的 MD5 值
* @param userId 用户ID
*/
public void deleteFileMark(String fileMd5, String userId) {
logger.debug("删除文件所有分片上传标记 => fileMd5: {}, userId: {}", fileMd5, userId);
try {
String redisKey = "upload:" + userId + ":" + fileMd5;
redisTemplate.delete(redisKey);
logger.info("文件分片上传标记已删除 => fileMd5: {}, userId: {}", fileMd5, userId);
} catch (Exception e) {
logger.error("删除文件分片上传标记失败 => fileMd5: {}, userId: {}, 错误: {}", fileMd5, userId, e.getMessage(), e);
throw new RuntimeException("Failed to delete file mark", e);
}
}
再去 file_upload 表更新文件状态
根据文件MD5和userId去 file_upload 将文件状态从 0 -> 1
// 更新文件状态
logger.info("更新文件状态为已完成 => fileMd5: {}, fileName: {}, fileType: {}, userId: {}", fileMd5, fileName, fileType, userId);
FileUpload fileUpload = fileUploadRepository.findByFileMd5AndUserId(fileMd5, userId)
.orElseThrow(() -> {
logger.error("更新文件状态失败,文件记录不存在 => fileMd5: {}, fileName: {}", fileMd5, fileName);
return new RuntimeException("文件记录不存在: " + fileMd5);
});
fileUpload.setStatus(1); // 已完成
fileUpload.setMergedAt(LocalDateTime.now());
fileUploadRepository.save(fileUpload);
logger.info("文件状态已更新为已完成 => fileMd5: {}, fileName: {}, fileType: {}", fileMd5, fileName, fileType);
返回预签名URL
// 生成预签名 URL(有效期为 1 小时)
logger.info("开始生成预签名URL => fileMd5: {}, fileName: {}, path: {}", fileMd5, fileName, mergedPath);
String presignedUrl = minioClient.getPresignedObjectUrl(
GetPresignedObjectUrlArgs.builder()
.method(Method.GET)
.bucket("uploads")
.object(mergedPath)
.expiry(1, TimeUnit.HOURS) // 设置有效期为 1 小时
.build()
);
logger.info("预签名URL已生成 => fileMd5: {}, fileName: {}, fileType: {}, URL: {}", fileMd5, fileName, fileType, presignedUrl);
return presignedUrl;
异常捕获
有两个 try 先是内层的,主要从文件合并开始
捕获的就是文件合并抛出的异常
catch (Exception e) {
logger.error("合并文件失败 => fileMd5: {}, fileName: {}, fileType: {}, 错误类型: {}, 错误信息: {}", fileMd5, fileName, fileType, e.getClass().getName(), e.getMessage(), e);
throw new RuntimeException("合并文件失败: " + e.getMessage(), e);
}
外层则是总的
catch (Exception e) {
logger.error("文件合并过程中发生错误 => fileMd5: {}, fileName: {}, fileType: {}, 错误类型: {}, 错误信息: {}", fileMd5, fileName, fileType, e.getClass().getName(), e.getMessage(), e);
throw new RuntimeException("文件合并失败: " + e.getMessage(), e);
}